
商城网站改版商品推荐行为方案规划,当我们商城需要改版商品的推荐时,首先基于用户行为推荐进行,基于固定的内容无法获取更加精准的推荐商品,那么我们可以换个角度来看待这个问题。网站建设公司认为把基于商品与商品的固定关系转变成参考人和商品、商品和商品之间的关系来进行推荐策略的构建,即基于用户的行为来判断商品的关系。用户的行为具有复杂多变的特性,但不代表它没有规律可循。常见的基于用户行为的策略主要分为关联规则和协同过滤。
▶关联规则关联规则是指通过收集的每个用户的一段购买数据,可以得出买过商品A的所有用户以及这些用户同时买了哪些其他商品,然后将这些商品合并就得出了一个同时被购买商品列表的排序。基于商品列表进行消重、去除低关联商品等,最终实现推荐商品列表输出。关联规则的核心策略就是计算关联度。关联度有两个常用指标:支持度和置信度。
●支持度(Support):买过商品A、同时买过商品B的人数/总的人数。
●置信度(Confidence):买过商品A、同时买过商品B的人数/买过商品A的人数。计算公式:关联度=Support×Confidence。下面我们举一个例子,看一下算法是如何运行的。Alice购买了商品item1,这个时候我们想计算item5是否应该推荐。根据公式,我们来计算一下支持度和置信度。支持度Support=2/4,置信度Confidence=2/2,需要说明的是,计算时要除去Alice本人。这样我们可以得到Support=0.5,Confidence=1,因此item5对于item1的关联度就是0.5×1=0.5,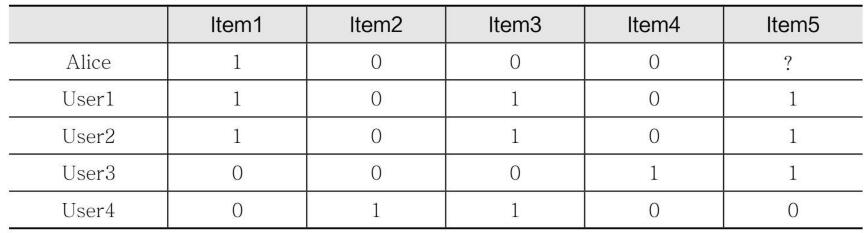 见表3-2。
见表3-2。
▶关联规则关联规则是指通过收集的每个用户的一段购买数据,可以得出买过商品A的所有用户以及这些用户同时买了哪些其他商品,然后将这些商品合并就得出了一个同时被购买商品列表的排序。基于商品列表进行消重、去除低关联商品等,最终实现推荐商品列表输出。关联规则的核心策略就是计算关联度。关联度有两个常用指标:支持度和置信度。
●支持度(Support):买过商品A、同时买过商品B的人数/总的人数。
●置信度(Confidence):买过商品A、同时买过商品B的人数/买过商品A的人数。计算公式:关联度=Support×Confidence。下面我们举一个例子,看一下算法是如何运行的。Alice购买了商品item1,这个时候我们想计算item5是否应该推荐。根据公式,我们来计算一下支持度和置信度。支持度Support=2/4,置信度Confidence=2/2,需要说明的是,计算时要除去Alice本人。这样我们可以得到Support=0.5,Confidence=1,因此item5对于item1的关联度就是0.5×1=0.5,
见表3-2。
从上面的例子我们可以看到,通过关联度可以发现人们最常用的购买组合是哪些。这对于一些品类单一的商品结构是非常适用的,策略的逻辑本身并不复杂,对技术的要求也不会特别高。但从计算量上来看,它需要对所有的商品进行遍历计算才能获取所有的指标,这对于离线的数据挖掘成本来说过大了。
▶协同过滤显而易见,将关联规则作为主要的算法是有些不合适的,我们需要寻找一个效率更高、成本更低的算法来作为主要的推荐算法,协同过滤就是目前主流的推荐算法。协同过滤的主要原理是运用群体的协同智慧,旨在通过一个群体的喜好判断来确定单体的特征和情况。网站建设公司提醒这个群体既可以是用户群体,也可以是商品群体。协同过滤有几个基本的假设:
●用户会对物品给出评价(隐性或显性);
●用户偏好一定时间内不会发生变化。协同过滤的处理主要包括两个部分:评测和群体搜索。我们来看一下协同过滤的处理流程, 如图3-19所示。
如图3-19所示。
▶协同过滤显而易见,将关联规则作为主要的算法是有些不合适的,我们需要寻找一个效率更高、成本更低的算法来作为主要的推荐算法,协同过滤就是目前主流的推荐算法。协同过滤的主要原理是运用群体的协同智慧,旨在通过一个群体的喜好判断来确定单体的特征和情况。网站建设公司提醒这个群体既可以是用户群体,也可以是商品群体。协同过滤有几个基本的假设:
●用户会对物品给出评价(隐性或显性);
●用户偏好一定时间内不会发生变化。协同过滤的处理主要包括两个部分:评测和群体搜索。我们来看一下协同过滤的处理流程,
如图3-19所示。
获取所有的用户信息,用户信息包括用户自行填写的内容、评价和消费记录等信息。对于新用户,可以通过冷启动的方式获取数据。同时要对用户的数据进行一些基本的预处理,主要的预处理为降噪和归一化。降噪主要是剔除一些异常数据,比如用户的误操作、未支付订单等;而归一化的目的是保证推荐结果在进行推荐计算的时候不会受到极值的影响而出现过大偏差。比如,订单的数量就远大于收藏的数量,需要将这样的信息通过处理变为一个相对合理的区间范围,一般会将归一化的数据分布变为[0,1]区间。常用的归一化方法有很多,比如对数归一、指数归一等。归一化的概念和地图的比例尺有些相似,其目的是在保证相对关系的情况下,将所有样本缩放到一定范围内,以便进行计算。数据处理完毕后,推荐系统就会根据信息对用户或商品进行评估打分。
这里面主要是基于已知的用户或者商品集合的信息,判断与当前用户或商品的相似度。推荐算法基于不同的相似度得到每个集合的分值,根据计算的分值判断与当前用户或商品的邻近群体。通过将邻近群体和当前商品或用户进行比对,完成推荐结果的输出。相似度的计算也是推荐算法的核心,相似度主要是指当前群体和已知群体之间的邻近程度。邻近算法也是随着技术发展逐步发展起来的,这里我们以KNN算法为例来看一下邻近算法的原理。KNN(全称K-NearestNeighbor,K-邻近算法)意思是K个最近的邻居,指的是每个样本都可以用它最接近的K个邻居来代表。该策略的思路是通过指定一个数量范围K,判断最相似的K个商品具备的共有特征,则认为查询的商品或用户本身也具有这个特征。简单地说,就是认为你跟你附近K个最近的群体具有相同特征。
这里面主要是基于已知的用户或者商品集合的信息,判断与当前用户或商品的相似度。推荐算法基于不同的相似度得到每个集合的分值,根据计算的分值判断与当前用户或商品的邻近群体。通过将邻近群体和当前商品或用户进行比对,完成推荐结果的输出。相似度的计算也是推荐算法的核心,相似度主要是指当前群体和已知群体之间的邻近程度。邻近算法也是随着技术发展逐步发展起来的,这里我们以KNN算法为例来看一下邻近算法的原理。KNN(全称K-NearestNeighbor,K-邻近算法)意思是K个最近的邻居,指的是每个样本都可以用它最接近的K个邻居来代表。该策略的思路是通过指定一个数量范围K,判断最相似的K个商品具备的共有特征,则认为查询的商品或用户本身也具有这个特征。简单地说,就是认为你跟你附近K个最近的群体具有相同特征。
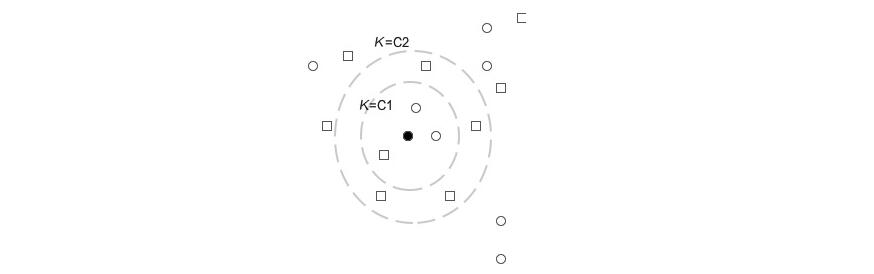 如图3-20所示,首先我们将所有的样本数据与当前需要比对的样本进行距离测算,根据测算距离生成一个由近及远的列表。所有样本比对完毕后,从当前列表中选取K个样本并判断当前样本中多数项的属性特征,将该属性特征赋予被比对的商品,完成推荐结果输出。我们通过图3-16来看一下邻近算法的运行原理。当范围K选取的是值C1时,我们认为当前比对样本的特征应该是圆形,因为在范围内圆形占多数项;而当我们把范围K的值调整为C2时,我们发现比对样的特征变为了正方形,因此KNN的邻近算法会因为K的选取范围而使结果产生巨大变化。图3-20虽然目前的主流协同过滤还是使用计算相似度来进行推荐,但策略上已经发生了变化。协同过滤按维度分为基于用户维度和基于商品维度。基于用户维度(User-Based:RowSimilarity)是指以用户为参照物来判断和当前用户相似的用户群体的喜好,从而向当前用户推荐相似用户群体喜好且当前用户未曾购买的商品。如果我们把用户和商品的关系列为一个矩阵,则按用户维度来看,它也可以看做是行相似性。
如图3-20所示,首先我们将所有的样本数据与当前需要比对的样本进行距离测算,根据测算距离生成一个由近及远的列表。所有样本比对完毕后,从当前列表中选取K个样本并判断当前样本中多数项的属性特征,将该属性特征赋予被比对的商品,完成推荐结果输出。我们通过图3-16来看一下邻近算法的运行原理。当范围K选取的是值C1时,我们认为当前比对样本的特征应该是圆形,因为在范围内圆形占多数项;而当我们把范围K的值调整为C2时,我们发现比对样的特征变为了正方形,因此KNN的邻近算法会因为K的选取范围而使结果产生巨大变化。图3-20虽然目前的主流协同过滤还是使用计算相似度来进行推荐,但策略上已经发生了变化。协同过滤按维度分为基于用户维度和基于商品维度。基于用户维度(User-Based:RowSimilarity)是指以用户为参照物来判断和当前用户相似的用户群体的喜好,从而向当前用户推荐相似用户群体喜好且当前用户未曾购买的商品。如果我们把用户和商品的关系列为一个矩阵,则按用户维度来看,它也可以看做是行相似性。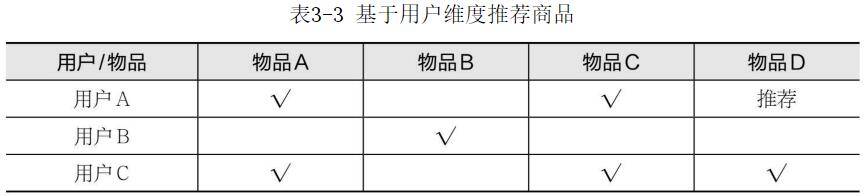 从表3-3中可以看到,用户A购买时,通过查询比对,发现用户A和用户C是相似群体,因此根据用户C的特征推荐商品D给用户A。深圳网站建设公司本文关于“网站改版商品推荐行为方案规划”经验就分享到这里,谢谢关注,博纳网络编辑整理。
从表3-3中可以看到,用户A购买时,通过查询比对,发现用户A和用户C是相似群体,因此根据用户C的特征推荐商品D给用户A。深圳网站建设公司本文关于“网站改版商品推荐行为方案规划”经验就分享到这里,谢谢关注,博纳网络编辑整理。当前文章链接:/construction/solution/14244.html
如果您觉得案例还不错请帮忙分享:
[声明]本网转载网络媒体稿件是为了传播更多的信息,此类稿件不代表本网观点,本网不承担此类稿件侵权行为的连带责任。故此,如果您发现本网站的内容侵犯了您的版权,请您的相关内容发至此邮箱【qin@198bona.com 】,我们在确认后,会立即删除,保证您的版权。