
当前位置:
网站推广公司认为作为一名网站SEO优化人员可以把自己看成一搜索引擎的贴身管家,而作为一名称职的管家必须了解服务对象的习性、爱好、健康程序等信息。同时还需要把它的运行规律、工作原理、习性、优缺点等铭记在心并多实践操作。下面简单地跟大家科普一下搜索引擎的工作原理即:爬行抓取、预处理、及服务输出。
1、爬行抓取
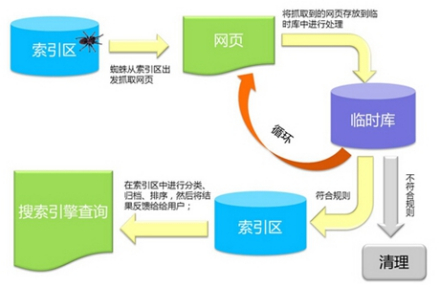
爬行抓取是搜索引擎工作最重要的一步,它把所有需要抓取的网页抓取回来进行处理分析。搜索引擎是通过一种特定的规律的软件跟踪网页的链接,从一个链接爬到另一个链接,像蜘蛛在蜘蛛网上爬行一样,所以被称为“蜘蛛”,也被称为是“机器人”。搜索引擎的爬行是被输入了一定的规则的,它需要遵从一些命令或文件的内容。
2、抓取存储
搜索引擎是通过蜘蛛跟踪链接爬行到网页,并将爬行的数据存入到原始页面数据库。其中的页面数据与用户浏览器得到的HTML是完全一样的。搜索引擎蜘蛛在抓取页面时,也做一定的重复内容的检测,一旦遇到权重很低的网站上有大量抄袭,采集或者复制的内容,很有可能就不再爬行了。
3、预处理
通过前面的爬行抓取流程,搜索引擎已经把网页全都抓取回来了,接下来的工作就是就是对这部分数据进行索引,其中包括多个处理流程。和爬行一样,预处理也是在后台完成的。预处理包括:关键词提取、去除停用词、分词、消除噪声、分析网页、建立倒排文件、链接关系计算最后进行特殊文件处理。
4、进行网页排名
用户在搜索框中输入关键字后,排名程序调用索引库数据,计算排名给用户,排名的过程与用户直接交互。但是,由于搜索引擎的数据量庞大,虽然达到每日都有小的更新,但是一般情况下,但是根据日,周,月阶段性不同幅度的更新。
以上就是搜索引擎的基本工作原理,希望能帮到我们网站建设搜索引擎优化的工作人员,熟知并掌握了搜索原理后能很快就在网络上广泛应用起来并获得来自搜索引擎搜索的大流量。
当前文章链接:/promotion/tgbz/11665.html
如果您觉得案例还不错请帮忙分享:
[声明]本网转载网络媒体稿件是为了传播更多的信息,此类稿件不代表本网观点,本网不承担此类稿件侵权行为的连带责任。故此,如果您发现本网站的内容侵犯了您的版权,请您的相关内容发至此邮箱【qin@198bona.com 】,我们在确认后,会立即删除,保证您的版权。